Most AI coding tools are generation engines. You describe what you want, they produce code. This works for isolated functions, boilerplate, and anything where the context fits in a prompt.
It breaks down when the problem is understanding an existing system - navigating a codebase you didn’t write, debugging a failure with no obvious error message, figuring out why something that worked in isolation fails in the larger system. These are comprehension problems, not generation problems. And comprehension requires structure, not just pattern matching.
The projects here are attempts to build the infrastructure for that kind of AI-assisted reasoning.
All tools run on local LLMs (LM Studio + Ollama) - no external API calls, no data leaving the machine. In the German automotive context, where sending engineering data to cloud APIs is a GDPR liability, this is a genuine constraint, not just a preference.
The AI Toolchain: How It Fits Together
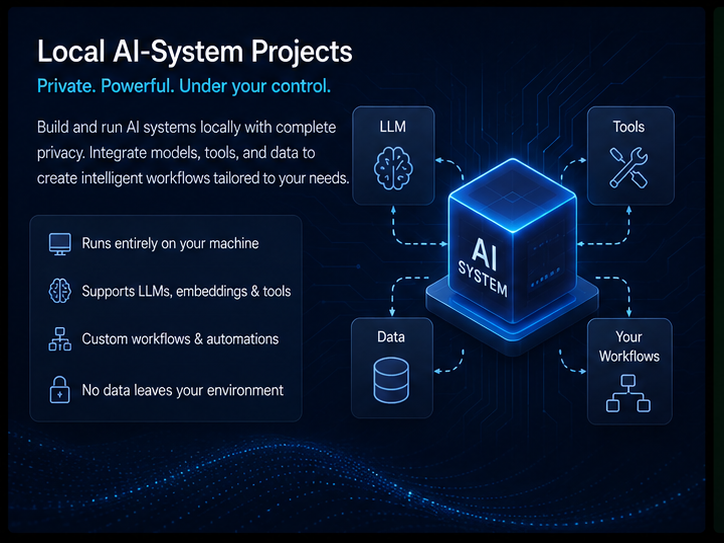
The tools aren’t independent - they’re designed to compose. The Indexer provides structural context. The Analyzer adds runtime behavior. Together they feed a local LLM with information it couldn’t extract from a raw codebase dump. The RAG layer adds document-level retrieval across notes, papers, and technical references.
Codebase Indexer
Problem: Large codebases are opaque. You can read files sequentially, but you can’t reason about dependency structure, identify which modules are most central, or understand what a change to one function propagates to - not without analysis tooling.
What it does: Static analysis of Python codebases - symbol extraction, dependency graph construction, importance scoring (which functions are most connected / most depended on), and a query layer for asking structural questions. The output isn’t just a file listing; it’s a map of the codebase that an agent can use to navigate and reason.
Why it matters for agents: An agent with access to a structural index can form a plan before touching code. It can identify the right entry point, understand the blast radius of a change, and avoid making edits that look locally correct but break something three layers up. This is the difference between an agent that codes and an agent that understands.
Hybrid Code Analyzer
The gap: Static analysis tells you about structure. It doesn’t tell you what happens when the code actually runs - which paths get executed, what types actually flow through, which imports fail in the current environment.
What it does: Combines static analysis (AST-level) with dynamic analysis (runtime instrumentation). Running both together reveals things neither can find alone: a function that statically looks correct but fails on specific input types, an import chain that works in the dev environment but not in production, a path that’s never exercised by tests and contains a latent bug.
The key design decision: The Indexer and Analyzer are deliberately kept separate tools. They produce different information - structural vs. behavioral - and combining them into a single pass loses the ability to correlate them independently. Run both, compare outputs, find the discrepancies. That’s where bugs live.
RAG Chatbot & Marginalia
The seed of the local retrieval stack - document ingestion, chunking, embedding, and local LLM inference over engineering notes, papers, and technical references.
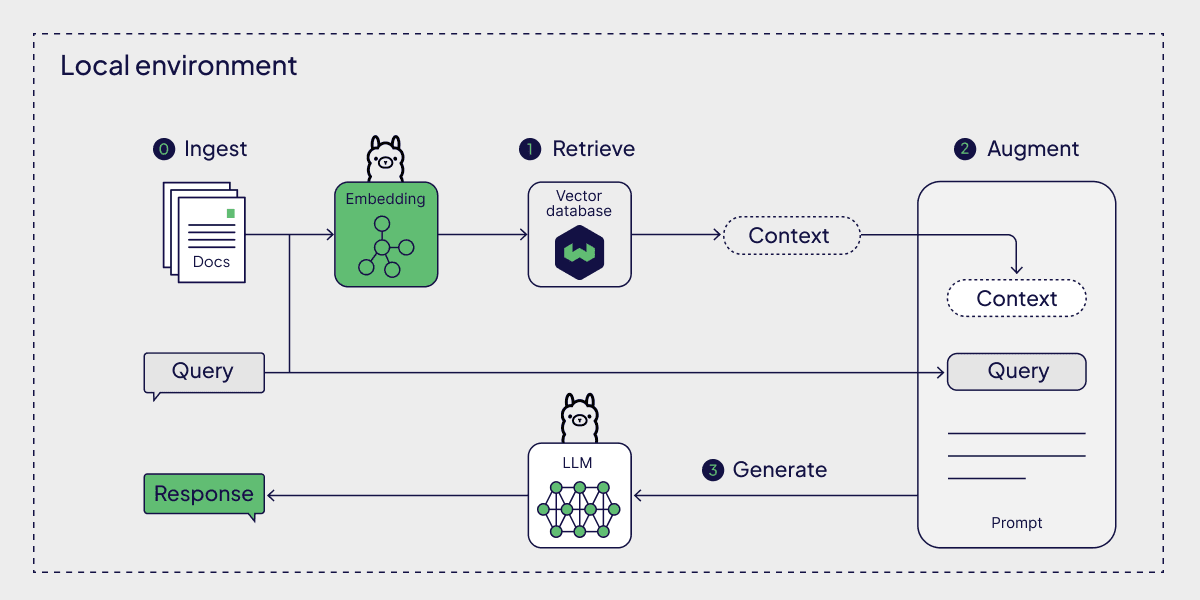
What it does: Retrieves relevant context from a personal knowledge base - papers, project notes, simulation references - and injects it into a local LLM query. No cloud, no external embeddings, no data leakage.
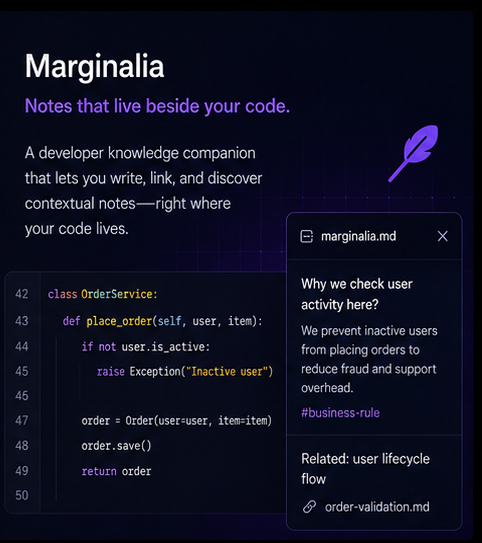

Marginalia extends this into structured annotation: highlights, notes, and concept links across technical documents - turning passive reading into a searchable, queryable personal knowledge layer.
Battery Expert AI
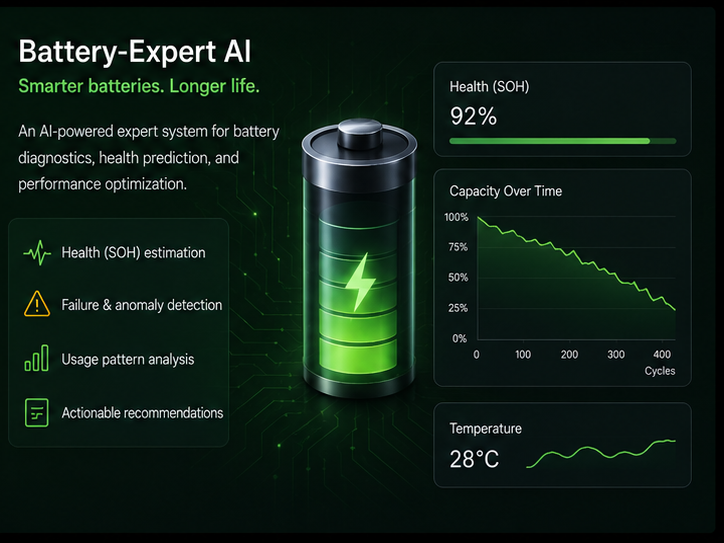

A domain-specific AI assistant trained on battery electrochemistry, simulation methodology, and OEM requirements - running locally. The goal: a technical interlocutor that understands Butler-Volmer, DFN models, and aging mechanisms without needing to be taught the basics in every prompt.
This is where the domain expertise meets the local AI infrastructure. The same tools that help with code reasoning apply to engineering reasoning - if the context is right.

The Pattern Across These Projects
All of these systems share a design philosophy: structure before generation. Understanding before output. Whether it’s a codebase, a battery operating envelope, or a project portfolio - the goal is to build representations that preserve the structural relationships, and then reason from those representations.
This is the direction AI-assisted engineering should go: not replacing the engineer’s judgment, but giving it better information to work from.